我成為工程師的時間剛好是 ChatGPT 剛問世的時候。當時它還不怎麼好用。但到了現在,伴隨著各種 AI 工具的問世。在激烈的市場競爭下,AI 的能力也隨之大幅提升,甚至已經成為我每天 coding 不可缺少的夥伴。但隨之我也發現一個很大的問題。作為一個 code reviewer,我發現很多工程師的程式碼品質沒有因為 AI 的幫助而提高。甚至讓我覺得 AI 在扼殺他們的成長。
AI 確實能加速開發非常非常多,但如果你不具有一定程度的批判性和扎實的技術能力的話。你只會越來越依賴 AI,不斷靠自身微薄的知識基礎,在跟 AI 溝通,你甚至無法發揮AI 所有的潛力。根據我的自身經驗,單靠 AI 是沒辦法寫出一個真正 robust 的產品級軟體。所以我想找一個方法可以有效的做出產品級的軟體。因此選擇了學習 Effect 這個 TypeScript 套件,作為這 30 天挑戰的主題。
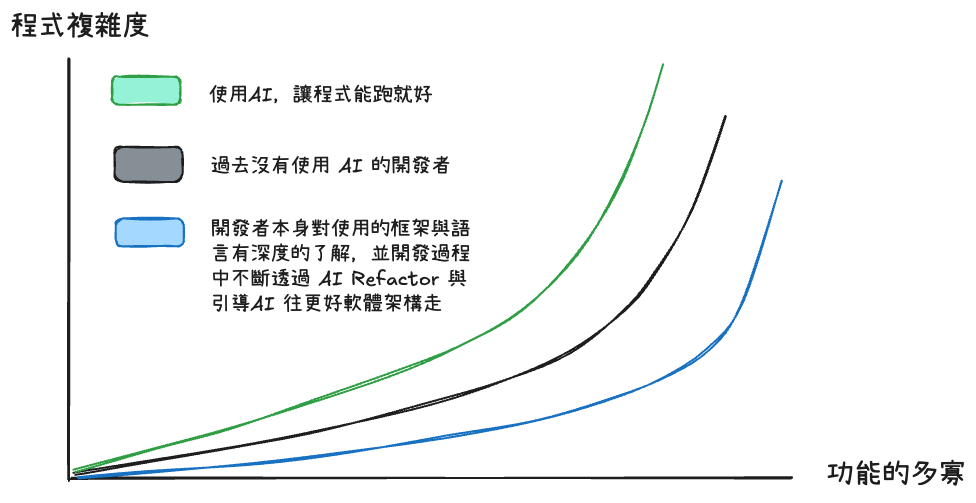
我畫了一張圖來說明將 AI 導入程式開發,但卻沒有好好 review code 會對程式碼品質有什麼樣的影響。
這張圖以橫軸為「功能的多寡」; 縱軸為「程式複雜度」呈現:當功能逐步增加時,若只是「使用 AI,讓程式能跑就好」(綠線),複雜度會很快地提升,因為大量臨時解法與複製貼上的行為造成技術債堆積;傳統「過去沒有使用 AI 的開發者」(黑線)雖然成長較緩,但仍會隨功能擴張逐步變陡;相對地,「對框架與語言有深刻理解、並在開發過程持續透過 AI 做 Refactor、主動引導 AI 朝更好架構前進的開發者」(藍線),能把複雜度長時間維持在較低斜率,延後拐點出現。AI 並非萬靈丹;只求「能跑」會讓複雜度飆升,而具備工程原則與架構紀律,並以 AI 作為重構與品質守門的工具,才能把系統複雜度有效壓在健康範圍內。
講了這麼多,其實就是想點出我今天的主題,什麼是產品級軟體。又要怎麼實現呢?
就我一個以 TypeScript 作為我的主力程式語言的工程師來說,TypeScript 讓我在編譯期抓到型別錯誤、擁有出色的 IDE 體驗。但它無法對產品級軟體的六大特質提供決定性的幫助。我們都知道程式能跑 ≠ 系統能長期穩定演進。TypeScript 強在型別安全與開發體驗。但要達成我們所期望的 Product-grade 軟體服務,需要靠得是更加全面的設計考量與讓程式碼能更加一致的工程方法。
首先是型別安全與資料驗證。當系統與各式各樣的輸入與外部來源互動時,唯有以一致的 Schema 作為邊界,才能把關資料品質並將風險前置到最靠近輸入的地方;錯誤應在解碼與驗證階段被揭露,並透過同一條錯誤回報通道被觀測與處理。環境設定也不例外,應以強型別方式載入並與 Schema 對齊,如此才能避免陰錯陽差的設定值在執行期才爆雷。
接著談錯誤處理與系統韌性。錯誤不等於災難,前提是我們能分辨它們的性質:哪些屬於暫時性、可重試;哪些是結構性、不可重試,必須立即失敗並啟動補救或回退。針對暫時性失敗,重試絕不是無腦地「再試一次」,而是要有節制地安排節奏。指數退避的精神,是在每次失敗後把重試間隔拉長,例如 1 秒、2 秒、4 秒……以倍數遞增,讓下游有時間恢復;再加上一點隨機抖動,將重試時間分散到 3.8 秒、4.2 秒之類的不同點上,避免所有用戶在第 4 秒同時衝回來,觸發所謂的「流量雪崩」。當下游持續不穩時,熔斷器就像電路跳脫的保護裝置:暫時打斷請求、過一段時間再以半開狀態試探,恢復後才全面合上。這些策略彼此呼應,讓錯誤被局部吸收與緩衝,而不是在整個系統內無限放大。
與韌性相伴的,是逾時與中斷控制。沒有逾時(timeout)的外部呼叫等同於將資源無限期佔用,最終拖垮整體吞吐;因此每一個對外互動都該有明確的 timeout 與截止時間(deadline)。當上游或使用者改變主意時,請求必須可以被取消(cancellation),中斷訊號(interrupt signal)要能安全地撤回正在進行的工作,並確保所有資源都被妥善釋放。這讓系統維持可預測的行為,也為後續診斷留下足跡。
再來是併發控制。當同一時間湧入的工作超過系統可以同時承擔的上限,就會出現競態、鎖競爭與資源飢餓等問題,甚至直接被外部的 rate limit(Rate limiting)擋下。佇列(Queue)像排隊買票,先入隊、再依序或分批處理,能把尖峰流量削平;信號量(Semaphore)則像停車場的剩餘車位,限制同時進場的數量,一旦滿了就等待。兩者搭配能夠避免瞬間把後端壓垮,並且與前述的退避(Exponential Backoff)、抖動(Jitter)與熔斷(Circuit Breaker)形成互補。關鍵業務流程也應設計為冪等(Idempotency),讓重試不會產生副作用,並善用快取(Caching)去重重複請求,減少不必要的負載。
要讓上述機制真正發揮作用,必須有可觀測性做後盾。日誌(Logging)負責記錄事件與上下文,指標(Metrics)反映健康度與容量,追蹤(Tracing)則畫出一個請求在系統內的旅程:從前端、API Gateway,到後端的服務 A、服務 B,再到資料庫,每一段的耗時與屬性都被標記清楚。我們往往能一眼看出壅塞究竟發生在資料庫讀寫,還是卡在外部 API,進而用數據驅動調整與擴容。採用像 OpenTelemetry 這樣的標準,能讓工具與生態自然對接,避免自創體系所帶來的碎片化成本。
最後是依賴注入。以分層方式管理服務邊界與依賴圖,讓模組之間的耦合降到最低;同一套介面在不同環境可以替換不同實作(真實服務、測試替身、staging 版本),既提升測試性,也讓部署與治理更有彈性。這種組態化的設計,會貫穿前述所有主題:你能在不動業務邏輯的情況下,為觀測、資安或配額策略換上不同的實現,系統也因此更容易隨需求而演進。
產品級軟體不是「能跑就好」或只靠型別系統就能達成,而是用一套可複製的工程方法,讓複雜度在功能與人數成長下仍然受控。六大特質(可預測、可觀測、可重構、可測試、直覺、可擴展)是評估標準;要落地,則必須把找到方法把這些觀念具體轉化成開發上 Default 的行為。當我們找到「做對變容易、做錯變困難」的開發方式,便是開發團隊邁向產品級軟體的第一步。我要努力加油!
感謝 未知作者 的精彩分享!
資安議題越來越重要,這樣的分享很有價值。
實際的程式碼範例很有幫助,讓理論更容易理解。
遇到的問題和解決方案分享很實用,相信很多人都會遇到類似的情況。
也歡迎版主有空參考我的系列文「南桃AI重生記」:https://ithelp.ithome.com.tw/users/20046160/ironman/8311
如果覺得有幫助的話,也歡迎訂閱支持!

